一、作业内容
- 作业①:
- 要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
- 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
- 输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
|
序号 |
股票代码 |
股票名称 |
最新报价 |
涨跌幅 |
涨跌额 |
成交量 |
成交额 |
振幅 |
最高 |
最低 |
今开 |
昨收 |
|
1 |
688093 |
N世华 |
28.47 |
62.22% |
10.92 |
26.13万 |
7.6亿 |
22.34 |
32.0 |
28.08 |
30.2 |
17.55 |
|
2...... |
- 代码:
from selenium import webdriver from selenium.webdriver.common.by import By import time import sqlite3 driver = webdriver.Chrome() # url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board' # driver.get(url) conn = sqlite3.connect('stocks.db') cursor = conn.cursor() cursor.execute(''' CREATE TABLE IF NOT EXISTS stocks ( 所属部分 TEXT,id INTEGER ,代码 TEXT,名称 TEXT,最新价 REAL,涨跌幅 REAL,涨跌额 REAL,成交量 REAL,成交额 REAL,振幅 REAL,最高 REAL, 最低 REAL,今收 REAL,昨收 REAL ) ''') def spider(name, url): driver.get(url) time.sleep(2) tr_list = driver.find_elements(By.XPATH, "//*[@id='table_wrapper-table']/tbody/tr") for tr in tr_list: data = tr.text data = data.split(" ") cursor.execute(''' insert into stocks( 所属部分, id, 代码 ,名称 ,最新价 ,涨跌幅 ,涨跌额 ,成交量 ,成交额 ,振幅 ,最高 ,最低 ,今收 ,昨收 ) VALUES(?,?,?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?) ''', ( name, data[0], data[1], data[2], data[6], data[7], data[8], data[9], data[10], data[11], data[12], data[13], data[14], data[15])) if __name__ == "__main__": typeurl = ['hs_a_board', 'sh_a_board', 'sz_a_board'] name = ['沪深京A股', '上证A股', '深证A股'] for i in range(0, 3): url = 'http://quote.eastmoney.com/center/gridlist.html#' + typeurl[i] spider(name[i], url) conn.commit() - 运行结果:
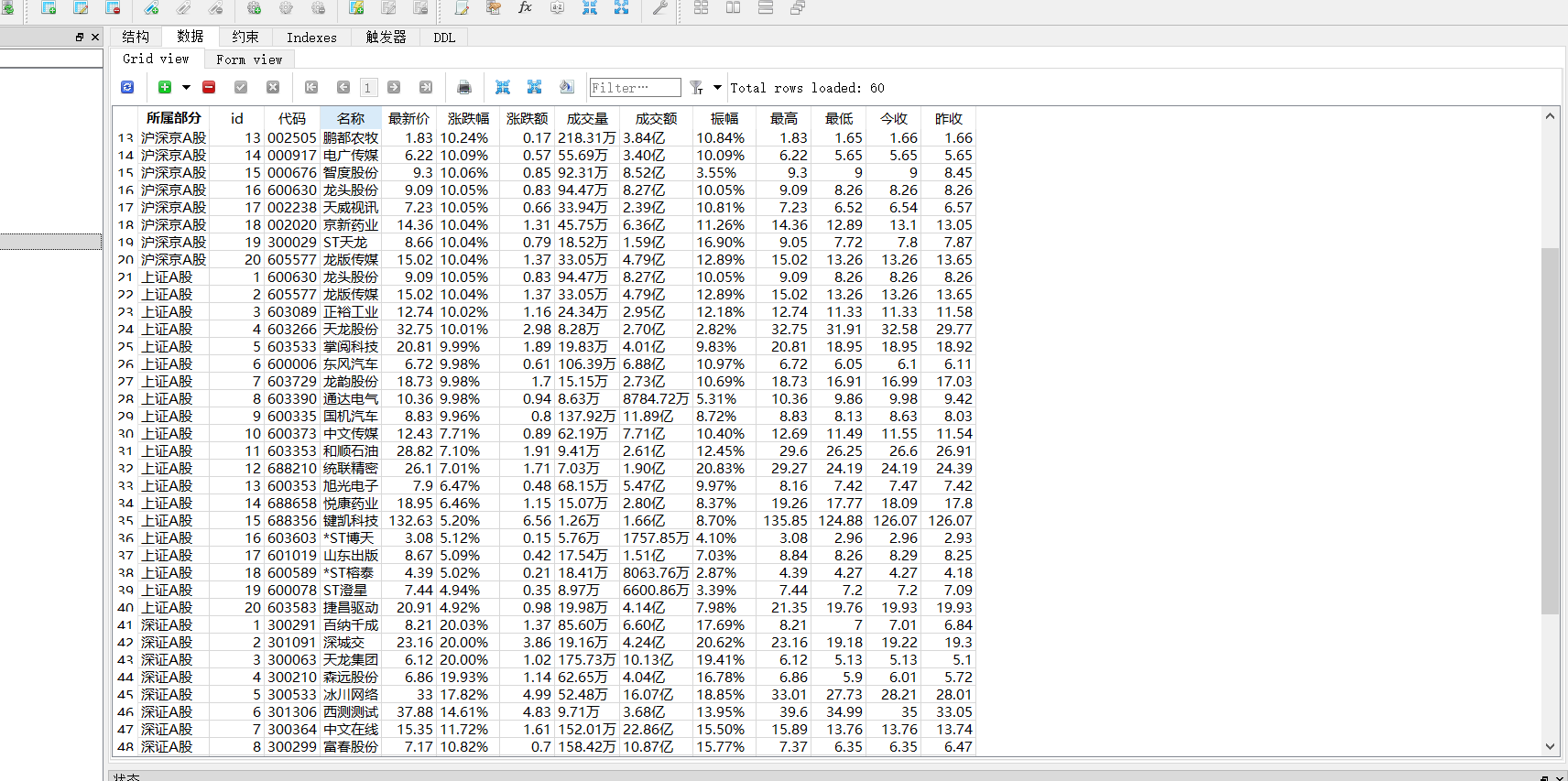
- 心得体会:在编写这段代码的过程中,我理解了几个模块:
模块化设计:将爬虫功能封装成一个名为spider的函数,使得代码结构更加清晰。同时,将数据库操作部分也封装成了一个独立的模块,便于后续维护和升级。
异常处理:在网络不稳定或服务器响应慢的情况下,使用time.sleep(2)来等待页面加载完成。虽然这种方法简单易用,但在实际应用中,可能需要更复杂的异常处理机制,如设置超时时间、重试策略等。
数据清洗:在将爬取到的数据插入到数据库之前,需要对数据进行清洗。例如,可以使用正则表达式或其他方法去除多余的空格和换行符,确保数据的一致性。
代码可扩展性:通过添加更多的功能模块,使程序更加完善。例如,可以考虑将爬虫部分封装成一个独立的类或模块,便于后续的维护和升级。
- 作业②:
- 要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
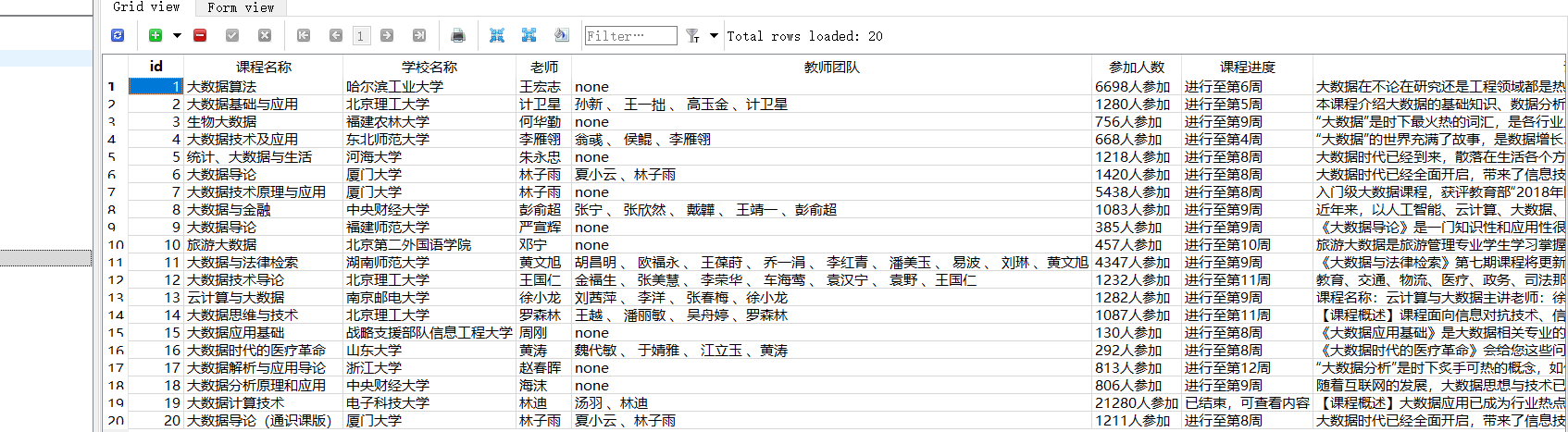
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
- 候选网站:中国mooc网:https://www.icourse163.org
- 输出信息:MYSQL数据库存储和输出格式
|
Id |
cCourse |
cCollege |
cTeacher |
cTeam |
cCount |
cProcess |
cBrief |
|
1 |
Python数据分析与展示 |
北京理工大学 |
嵩天 |
嵩天 |
470 |
2020年11月17日 ~ 2020年12月29日 |
“我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” …… |
|
2...... |
- 代码:
from selenium import webdriver from selenium.webdriver.common.by import By import sqlite3 import time driver = webdriver.Chrome() driver.get('https://www.icourse163.org/') time.sleep(1) button = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div') button.click() time.sleep(1) frame = driver.find_element(By.XPATH,"//div[@class='ux-login-set-container']//iframe") driver.switch_to.frame(frame) account = driver.find_element(By.ID, 'phoneipt').send_keys('1111')#这边1111代表输入账号,我就不把真账号弄进去 password = driver.find_element(By.XPATH, '//input[@placeholder="请输入密码"]').send_keys("1111") # 这边1111代表输入密码,我就不把真密码弄进去 button1 = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a') button1.click() time.sleep(1) url = 'https://www.icourse163.org/search.htm?search=%E5%A4%A7%E6%95%B0%E6%8D%AE#/' driver.get(url) conn = sqlite3.connect('课程信息.db') cursor = conn.cursor() cursor.execute(''' create table course( id INTEGER,课程名称 text, 学校名称 text,老师 text,教师团队 text,参加人数 text, 课程进度 text, 课程简介 text ) ''') count = 0 link_list = driver.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]') for link in link_list: count += 1 course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text try: team_member = link.find_element(By.XPATH, './/span[@class="f-fc9"]/span').text team_member = team_member + ' 、' + teacher except Exception as err: team_member = 'none' attendees = link.find_element(By.XPATH, './/span[@class="hot"]').text attendees.replace('参加', '') process = link.find_element(By.XPATH, './/span[@class="txt"]').text introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text cursor.execute(''' insert into course( id ,课程名称 , 学校名称 ,老师 ,教师团队 ,参加人数 , 课程进度 , 课程简介 ) VALUES(?,?,?, ?, ?, ?, ?, ?) ''', (count, course_name, school_name, teacher, team_member, attendees, process, introduction )) conn.commit() cursor.close() conn.close() - 运行结果:
- 心得体会:在这段代码中,我使用了XPath来定位网页上的元素。通过学习XPath语法和示例,我了解到了如何使用XPath来精确地定位到目标元素,从而提高了代码的执行效率。同时遇到了一些可能出现异常的地方,如查找团队成员时可能会找不到对应的元素。为了确保代码的稳定性,我在这些地方添加了异常处理机制,当出现异常时,将团队成员设置为'none'。在编写过程中,不断尝试运行代码并观察结果,以便及时发现问题并进行修正。同时,我也反思了自己的代码实现,思考是否有更优化的方法来提高代码的性能和可读性。
- 作业③:
- 要求:
- 掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建:
- 任务一:开通MapReduce服务
- 实时分析开发实战:
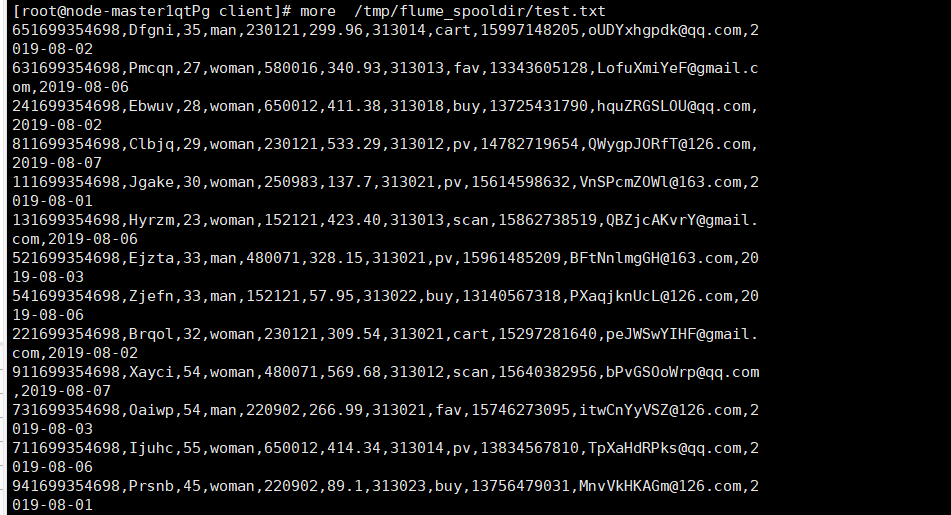
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka

- 任务三: 安装Flume客户端


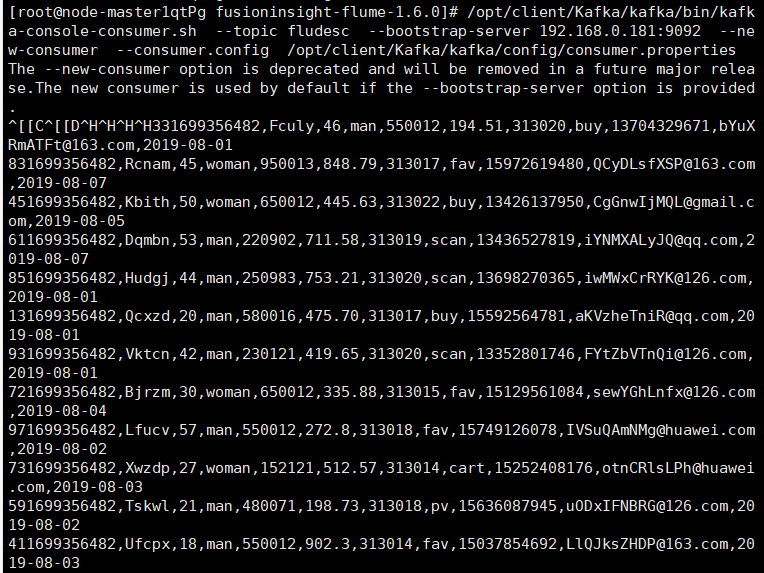
- 任务四:配置Flume采集数据
- 心得体会:根据word一步步做,感觉难度不难,注意细节就行。